
Métodos Essenciais de Machine Learning são fundamentais em processos comerciais e amplamente utilizado em outras áreas como o exemplo que trazemos neste artigo na área de saúde.
O Machine Learning tem revolucionado diversas indústrias, permitindo a automação de processos e a extração de insights valiosos a partir de dados.
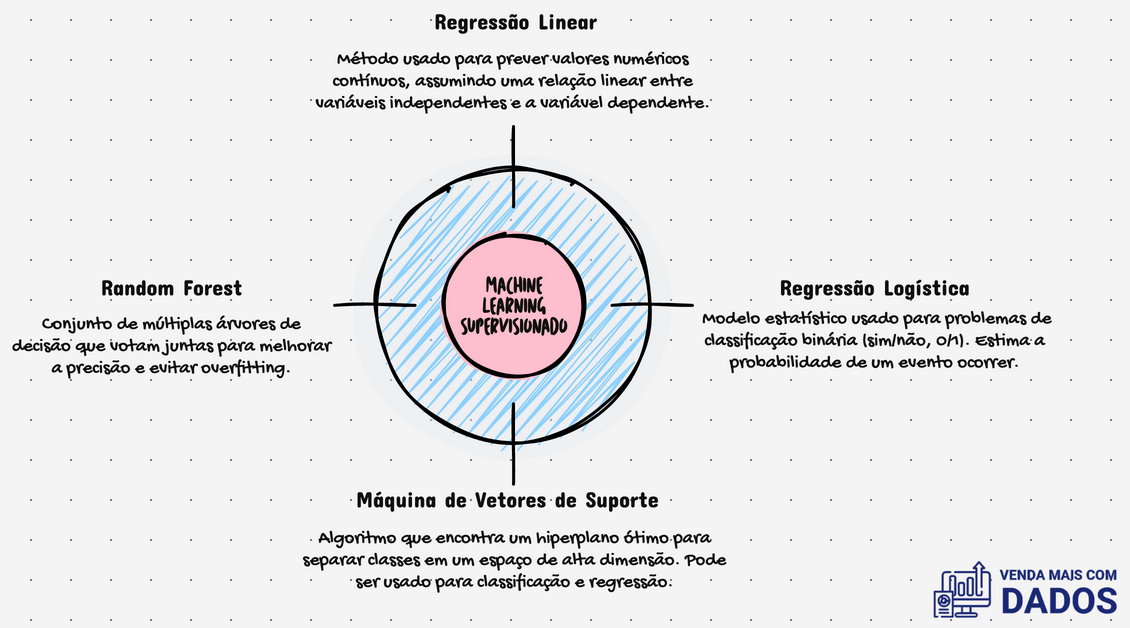
Entre os inúmeros algoritmos disponíveis, quatro se destacam pelo seu amplo uso e aplicabilidade: Regressão Linear, Regressão Logística, Random Forest e Máquina de Vetores de Suporte (SVM).
A seguir, apresentamos um resumo de cada um desses métodos, suas principais aplicações e casos reais de uso.
Métodos Essenciais de Machine Learning para vendas.
Antes de começar, convidamos vocês a ler um artigo muito interessante sobre Auto Machine Learning, que facilita o processo de uso deste método e torna mais acessível o uso de Machine Learning.
Métodos Essenciais de Machine Learning: Regressão Linear
A Regressão Linear é um dos modelos mais simples e fundamentais do Machine Learning. Ele busca encontrar a relação entre uma variável dependente e uma ou mais variáveis independentes, ajustando uma linha reta aos dados.
Esse modelo assume que há uma relação linear entre as variáveis, utilizando a equação:
Y = βo + β1X1 + β2X2 + … + βnXn + ε
onde Y é a variável dependente, X são as variáveis independentes, β são os coeficientes do modelo e ε é o erro residual.
Por exemplo, é possível utilizar este método para previsão de preços de imóveis com base em variáveis como metragem, localização e número de quartos.
A Zillow, uma empresa de tecnologia imobiliária, usa modelos de regressão linear para estimar os valores de propriedades em tempo real, ajudando compradores e vendedores a tomarem decisões informadas.

Foto de Ярослав Алексеенко na Unsplash
Por exemplo, no vídeo abaixo trago uma aula muito interessante sobre o uso de Regressão Linear aplicada em vendas no Excel.
Detecção de fraudes com Regressão Logística
A Regressão Logística é um método estatístico utilizado para classificação binária, ou seja, quando o objetivo é prever uma resposta categórica, como “sim” ou “não”.
Assim, diferente da regressão linear, a regressão logística utiliza a função sigmoide para mapear os valores para um intervalo entre 0 e 1, tornando-se ideal para problemas de classificação.
Por exemplo, este método é fundamental na detecção de fraudes em transações bancárias, ajudando no processo de classificação de operações como legítimas ou fraudulentas.
O PayPal emprega regressão logística em seus sistemas de segurança para identificar padrões suspeitos em transações financeiras e prevenir fraudes.
Métodos Essenciais de Machine Learning: Random Forest
O Random Forest é um modelo de aprendizado de máquina baseado em múltiplas árvores de decisão.
Assim, ele cria diversas árvores durante o treinamento e combina suas previsões para aumentar a precisão e reduzir o risco de overfitting.
Portanto, ideia central é dividir aleatoriamente os dados e treinar diferentes árvores para criar um consenso de decisão.
O modelo utiliza o conceito de bagging (Bootstrap Aggregating), onde cada árvore recebe um subconjunto diferente dos dados, e a previsão final é feita por votação majoritária (classificação) ou média (regressão).
Por exemplo, exemplo O IBM Watson Health utiliza Random Forest para analisar dados clínicos e auxiliar médicos na tomada de decisões mais assertivas sobre diagnósticos e tratamentos.
A imagem abaixo foi retirada de uma imagem com outros gráficos existentes no artigo original e nos mostra vários casos de câncer em diferentes estágios e os resultados da recomendação para cada um.

Resultado dos processos de recomendação para diferentes tipos e estágios de câncer.
Métodos Essenciais de Machine Learning: Máquina de Vetores de Suporte (SVM)
A Máquina de Vetores de Suporte (SVM) é um modelo utilizado principalmente para classificação, encontrando o hiperplano que melhor separa os dados em diferentes categorias.
Assim, este método maximiza a margem entre as classes, garantindo uma generalização mais eficiente para novos dados.
Por exemplo, se os dados não forem linearmente separáveis, o SVM pode utilizar funções de kernel para transformar os dados em um espaço dimensional superior, onde a separação se torna possível.
O Google utiliza SVMs em seu sistema de reconhecimento de caracteres para melhorar a precisão do Google Translate na conversão de textos manuscritos e impressos em diferentes idiomas.
Conclusão
Os métodos de Machine Learning abordados neste artigo são amplamente utilizados em diversas indústrias, proporcionando ganhos significativos em precisão, automação e inteligência nos processos.
Assim, cada um desses algoritmos tem suas próprias vantagens e casos de uso específicos, sendo essencial escolher a abordagem correta para cada problema.
Portanto, para você que quer aprofundar seus conhecimentos em Machine Learning, é importante sempre se atualizar com nossos conteúdos no YouTube e na Udemy:
0 comentários