
As árvores de decisão podem te ajudar a vender mais, e hoje vou te mostrar o porquê, e compartilharei também os códigos para que você realize seu primeiro estudo.
Primeiramente, agradeço a paciência de vocês, uma vez que não pude postar nada novo nas duas últimas semanas.
Foram semanas de viagens corporativas, e exigiram muito da minha agenda, tornando quase impossível voltar aqui e criar um texto de qualidade para vocês.
Lembrando que, nosso objetivo no Blog é sempre trazer insights, sem o uso de frases de efeito ou modismo, para que você possa entender os benefícios da utilização dos dados em vendas.
Vamos começar com uma breve revisão do que postamos anteriormente, caso você não tenha tido a oportunidade de ler os artigos anteriores que criamos sobre o tema.
Para quem quiser ler os textos, antes de continuar por aqui, basta seguir os links abaixo.
As árvores de decisão podem te ajudar a vender mais: Uma revisão rápida
Uma forma simples de definir uma árvore de decisão é como um método de Machine Learning que te ajudará de forma muito visual a tomar decisões a partir de seus dados.
Assim, em um processo de tomada de decisões bem estabelecido em sua estratégia comercial, você poderá fazer uso deste método para agilizar todo o processo.
Vamos revisar o processo abaixo:

Exemplo de árvore de decisão para uma atividade comercial.
Seria muito fácil tomar decisões a partir de um número pequeno de clientes.
Contudo, o que você faria para agilizar o processo em uma situação envolvendo milhares, ou até mesmo centenas de milhares de clientes?
Você utilizaria o processo de Árvores de Decisão para obter um resultado similar ao da imagem abaixo.
Resultados de uma árvore de decisão
Agora que temos este resultado, podemos tomar decisões com base nas informações disponíveis.
Mas como chegamos neste resultado?
Vamos agora conhecer um pouco o processo e os códigos utilizados.
As árvores de decisão podem te ajudar a vender mais: Processo e códigos
Todo processo de Análise de dados no Phyton começa com o carregamento das bibliotecas que serão utilizadas.
A partir delas que seremos capazes de criar a base de dados, realizar uma análise exploratória, criar gráficos e a árvore de decisão.
# Importando bibliotecas import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from scipy.stats import chi2_contingency from sklearn.tree import DecisionTreeClassifier, plot_tree from sklearn import tree from sklearn.preprocessing import LabelEncoder from sklearn.metrics import classification_report
A biblioteca específica para a criação da árvore de decisão que utilizaremos neste caso é a Skicitlearn, na qual aconselho você estudar toda a documentação dela neste link.
Por exemplo, além das ferramentas para criarmos nossa Árvore de Decisão, esta biblioteca pode te ajudar a trabalhar também com regressões lineares e clusterização, dois métodos muito úteis em vendas e já abordamos aqui no blog algumas vezes.

Ferramentas disponíveis na Biblioteca Skicit Learn
Inclusive, temos uma aula muito bacana de como realizar regressões lineares no Excel, para você que utiliza muito este software em seu dia a dia.
Importando ou criando a sua base de dados
Assim, uma vez que você já importou todas suas bibliotecas, é hora de importar ou criar sua base de dados.
Por exemplo, vamos criar uma base de dados para facilitar o nosso estudo aqui.
Portanto, você pode inserir o código abaixo no Colab.
# 1. Gerando base de dados
np.random.seed(42)
n_samples = 1000
dados = pd.DataFrame({
'Demonstrou_Interesse': np.random.choice(['Sim', 'Não'], size=n_samples, p=[0.7, 0.3]),
'Respondeu_Proposta': np.random.choice(['Sim', 'Não'], size=n_samples, p=[0.5, 0.5]),
'Tem_Objeções': np.random.choice(['Sim', 'Não'], size=n_samples, p=[0.4, 0.6])
})
def definir_acao(row):
if row['Demonstrou_Interesse'] == 'Não':
return 'Aquecer Lead'
elif row['Respondeu_Proposta'] == 'Sim':
return 'Fechar Direto'
elif row['Tem_Objeções'] == 'Sim':
return 'Trabalhar Objeções'
else:
return 'Fechar Venda'
dados['Ação_Final'] = dados.apply(definir_acao, axis=1)
print(dados.head())
Nele estaremos criando um Dataframe com 1000 clientes, com base em nosso processo.
Vejam que temos tando as respostas as perguntas do nosso fluxograma, assim como as acoes tomadas com base em um determinado tipo de resposta.
Análise Exploratória de Dados
Agora é o momento de estudar um pouco nossos dados e tirar algumas conclusoes com base nas informacoes que temos.
Por exemplo, criar gráficos que nos ajude entender quantos clientes demonstraram interesse em nossa proposta.
Assim, basta que você utilize os códigos abaixo.
# Quantos clientes demonstraram interesse?
# Cores suaves com contraste (ex: azul claro e azul escuro)
cores = ['#a6c8ff', '#00539b'] # azul claro e azul escuro
plt.figure(figsize=(6, 4))
ax = sns.countplot(
x='Demonstrou_Interesse',
data=dados,
palette=cores
)
# Títulos dos eixos
ax.set_xlabel("Demonstrou interesse?")
ax.set_ylabel("Número de Clientes")
# Título do gráfico
ax.set_title("Distribuição - Demonstrou Interesse")
# Remover linhas de grade do meio
ax.grid(False)
# Remover bordas superiores e laterais (opcional para visual mais limpo)
sns.despine()
plt.tight_layout()
plt.show()
# Quantos clientes responderam a proposta?
# Cores suaves com contraste (ex: azul claro e azul escuro)
cores = ['#a6c8ff', '#00539b'] # azul claro e azul escuro
plt.figure(figsize=(6, 4))
ax = sns.countplot(x='Respondeu_Proposta', data=dados, palette=cores)
ax.set_title('Distribuição - Respondeu Proposta') # em vez de plt.title
# Títulos dos eixos
ax.set_xlabel("Respondeu a Proposta?")
ax.set_ylabel("Número de Clientes")
# Remover linhas de grade
ax.grid(False)
# Remover bordas
sns.despine()
plt.tight_layout()
plt.show()
# Cores suaves com contraste (azul claro e escuro)
cores = ['#a6c8ff', '#00539b']
plt.figure(figsize=(6, 4))
# Plot com retorno do objeto Axes
ax = sns.countplot(x='Tem_Objeções', data=dados, palette=cores)
# Ajustar os rótulos do eixo X para "Não" e "Sim"
ax.set_xticklabels(['Não', 'Sim'])
# Título e rótulos dos eixos
ax.set_title('Distribuição - Tem Objeções')
ax.set_xlabel("Tem Objeções?")
ax.set_ylabel("Número de Clientes")
# Remover linhas de grade e bordas superiores/laterais
ax.grid(False)
sns.despine()
# Ajustar layout
plt.tight_layout()
# Exibir o gráfico
plt.show()
# Criar a tabela cruzada com normalização por linha
ct = pd.crosstab(dados['Demonstrou_Interesse'], dados['Tem_Objeções'], normalize='index')
# Definir a paleta de cores em tons de azul
palette = sns.color_palette("Blues", n_colors=ct.shape[1])
# Criar o gráfico de barras empilhadas
ax = ct.plot(kind='bar', stacked=True, color=palette, figsize=(8, 6))
# Títulos e rótulos
ax.set_title('Proporção de Objeções por Interesse', fontsize=14)
ax.set_xlabel('Demonstrou interesse?')
ax.set_ylabel('Proporção')
# Formatar o eixo y para mostrar porcentagens
ax.yaxis.set_major_formatter(plt.FuncFormatter(lambda y, _: '{:.0%}'.format(y)))
# Remover linhas de grade
ax.grid(False)
# Remover bordas superiores e laterais
sns.despine()
# Posicionar a legenda fora do gráfico
ax.legend(title='Tem Objeções', bbox_to_anchor=(1.05, 1), loc='upper left')
# Ajustar o layout para acomodar a legenda
plt.tight_layout()
# Exibir o gráfico
plt.show()
Minha sugestão é que você divida os códigos com base nas perguntas, para visualizar um gráfico de cada vez.
Também é interessante que você leia este nosso artigo sobre Data Storytelling para entender melhor algumas das estratégias que utilizamos para facilitar o entendimento destes gráficos.
Aproveite também para explorar o código ajustando cores, títulos e outras informações.
Se você, assim como eu, não for um profundo conhecedor de programação, dá um pulinho no ChatGPT, pede ajuda para alterar o código e uma explicação sobre as mudanças.
As árvores de decisão podem te ajudar a vender mais: Pré-processamento e processamento
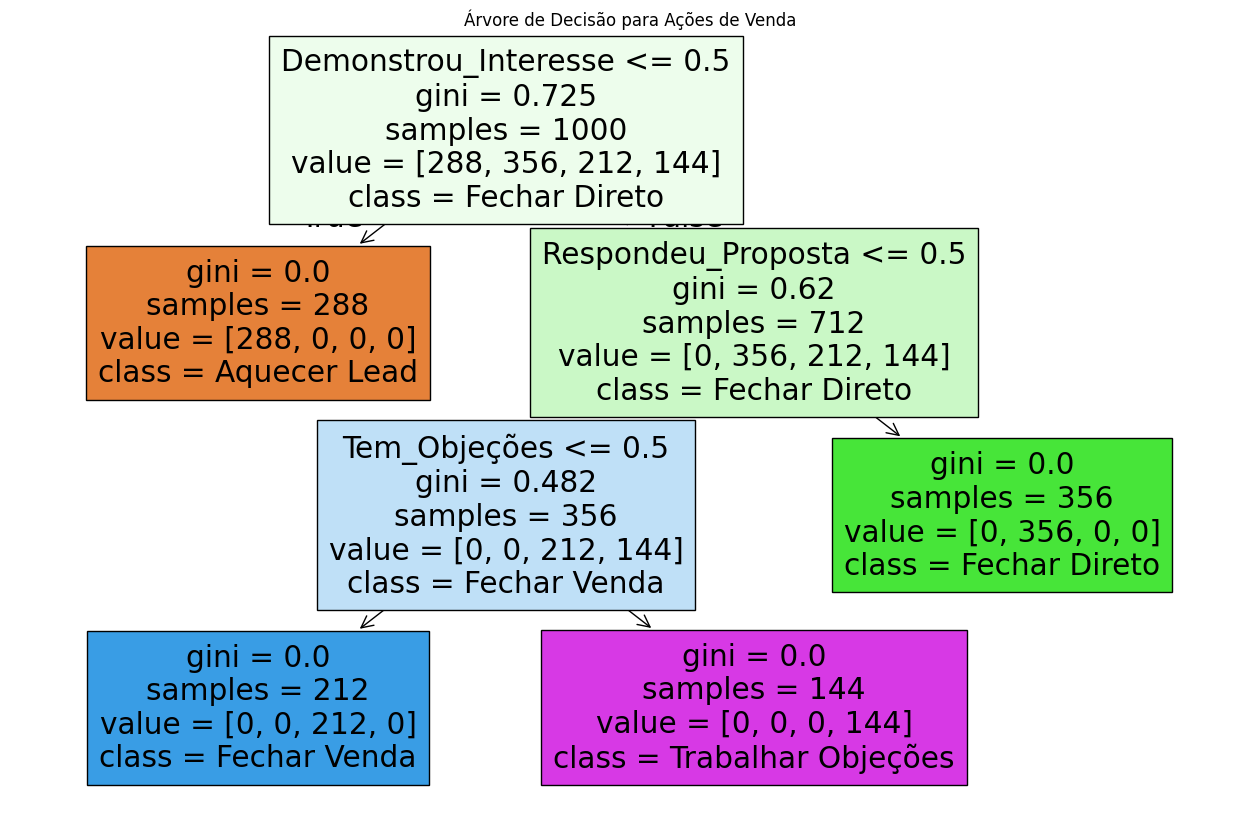
Chegou o momento mais esperado, o de visualizar nossa árvore de decisão.
Assim, começaremos realizando uma etapa de pré-processamento, onde ajustaremos nossos dados para utilização deste método de Machine Learning.
# 2. Pré-processamento da base de dados para criar Árvore de Decisão
le = LabelEncoder()
for coluna in ['Demonstrou_Interesse', 'Respondeu_Proposta', 'Tem_Objeções', 'Ação_Final']:
dados[coluna] = le.fit_transform(dados[coluna])
# Separando X e y
X = dados[['Demonstrou_Interesse', 'Respondeu_Proposta', 'Tem_Objeções']]
y = dados['Ação_Final']
Esta etapa é fundamental, pois nela definimos quais variáveis serão utilizadas para definir as ações que tomaremos.
De forma muito simples de explicar, a Ação Final depende das respostas que os nossos clientes forneceram para cada uma das perguntas.
Portanto, as perguntas estão como X e a Ação Final como y.
Agora, vamos treinar nosso modelo!
O treinamento do modelo é uma etapa essencial em qualquer processo de aprendizagem que realizamos em nossas análises.
Um código bem simples vai nos ajudar a realizar esta etapa.
# 3. Treinando a árvore clf = DecisionTreeClassifier(max_depth=5, random_state=42) clf.fit(X, y)
Finalmente, vamos criar nossa árvore.
# 4. Visualizando a árvore de decisão
plt.figure(figsize=(16, 10))
plot_tree(clf, feature_names=X.columns, class_names=['Aquecer Lead', 'Fechar Direto', 'Fechar Venda', 'Trabalhar Objeções'], filled=True)
plt.title("Árvore de Decisão para Ações de Venda")
plt.show()
Definindo ações a partir da árvore de decisão
Assim como podemos facilitar a tomada de decisoes a partir de um método de Machine Learning, podemos utilizar os resultados para criar gráficos que nos ajudem tomar decisões.
A última parte do código que você utilizará é para criar o gráfico abaixo, que te ajudará entender a quantidade de cliente em cada Ação final.

Definindo ações a partir da árvore de decisão
Por exemplo, basta que você utilize os códigos abaixo para criar o gráfico e criar uma tabela com base na informação que você obteve.
# Copiando os dados para não afetar os nomes reais
dados_numerico = dados.copy()
# Convertendo as colunas categóricas em números
colunas_categoricas = ['Demonstrou_Interesse', 'Respondeu_Proposta', 'Tem_Objeções', 'Ação_Final']
le = LabelEncoder()
for coluna in colunas_categoricas:
dados_numerico[coluna] = le.fit_transform(dados_numerico[coluna])
# Cria a coluna 'Ação_Final_Nome' com base na coluna numérica 'Ação_Final'
mapa_acoes = {
0: 'Fechar Venda',
1: 'Acompanhar',
2: 'Trabalhar Objeções',
3: 'Aquecer Lead'
}
dados['Ação_Final_Nome'] = dados['Ação_Final'].map(mapa_acoes)
plt.figure(figsize=(8, 6))
# Gráfico com nomes das ações e ordenado pela frequência
ax = sns.countplot(
x='Ação_Final_Nome',
data=dados,
order=dados['Ação_Final_Nome'].value_counts().index,
palette='Set2'
)
# Título e rótulos
plt.title('Distribuição das Ações Recomendadas')
plt.xlabel('Ação Final')
plt.ylabel('Quantidade')
plt.xticks(rotation=15)
# Adicionando porcentagens sobre cada barra
total = len(dados)
for p in ax.patches:
count = int(p.get_height())
perc = f'{100 * count / total:.1f}%'
ax.annotate(perc,
(p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='bottom', fontsize=10)
plt.tight_layout()
plt.show()
# Tabela final com leads e ações recomendadas
dados['Cliente_ID'] = ['Lead_' + str(i+1) for i in dados.index]
tabela_acoes = dados[['Cliente_ID', 'Demonstrou_Interesse', 'Respondeu_Proposta', 'Tem_Objeções', 'Ação_Final_Nome']]
# Exibir por ação
for acao in tabela_acoes['Ação_Final_Nome'].unique():
print(f"\n--- {acao} ---")
display(tabela_acoes[tabela_acoes['Ação_Final_Nome'] == acao])
#FIM
Novamente, a sugestão é que você divida estes códigos por etapa, e faça as modificações que achar interessante para entender um pouco melhor o resultado.
As árvores de decisão podem te ajudar a vender mais: Conclusao
Assim, chegamos ao fim deste artigo e desta série sobre Árvores de Decisão.
Nela compartilhamos diversos insights para você entender os benefícios deste processo em sua estratégia comercial.
Além disso, tentamos desmistificar um pouco a ideia de que o uso de Machine Learning em vendas é sempre muito complexo e nao deve ser explorado.
Para você que quer entender um pouco mais sobre Análise Exploratória de Dados no Phyton, aconselhamos nosso curso gratuito na Udemy, assim como o acesso a nosso Canal do Youtube e Perfil do Tiktok.
Neles, você encontrará muito conteúdo gratuito para aprender mais e utilizar dados em seu dia a dia.
0 comentários